Abstract
We present Inferflow, an efficient and highly configurable inference engine for large language models (LLMs). With Inferflow, users can serve most of the common transformer models by simply modifying some lines in corresponding configuration files, without writing a single line of source code. Compared with most existing inference engines, Inferflow has some key features. First, by implementing a modular framework of atomic build-blocks and technologies, Inferflow is compositionally generalizable to new models. Second, 3.5-bit quantization is introduced in Inferflow as a tradeoff between 3-bit and 4-bit quantization. Third, hybrid model partitioning for multi-GPU inference is introduced in Inferflow to better balance inference speed and throughput than the commonly-adopted partition-by-layer and partition-by-tensor strategies.
Inferflow
We list major requirements for an LLM inference engine and possible technologies to address them.
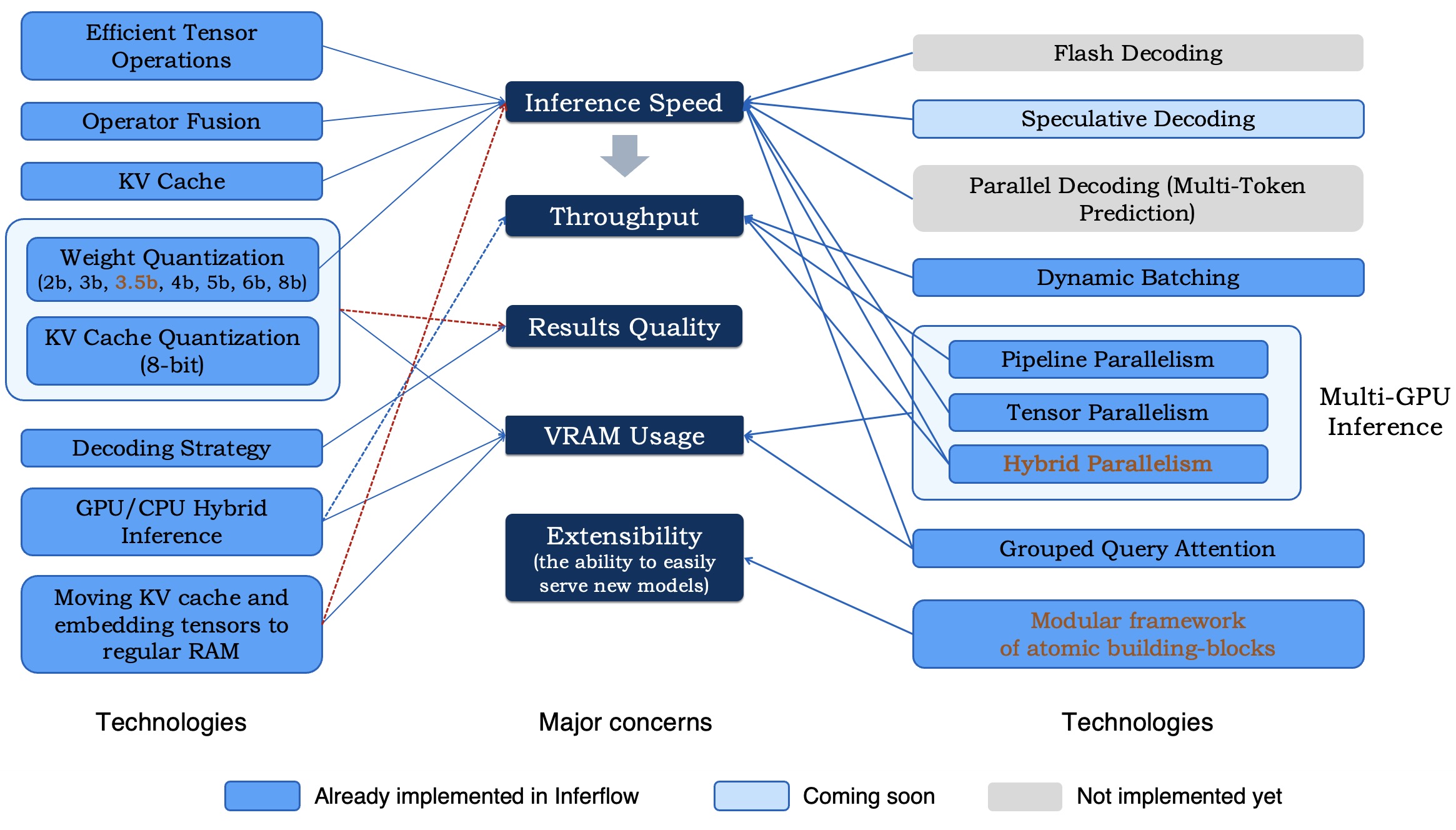
Implementation status of key technologies in Inferflow
Main Features
Comparison
| Model | New Model Support | Supported File Formats | Network Structures | Quantization Bits | Hybrid Parallelism for Multi-GPU Inference | Programming Languages |
|---|---|---|---|---|---|---|
| Huggingface Transformers | Adding/editing source codes | pickle (unsafe), safetensors | decoder-only, encoder-decoder, encoder-only | 4b, 8b | ✘ | Python |
| vLLM | Adding/editing source codes | pickle (unsafe), safetensors | decoder-only | 4b, 8b | ✘ | Python |
| TensorRT-LLM | Adding/editing source codes | decoder-only, encoder-decoder, encoder-only | 4b, 8b | ✘ | C++, Python | |
| DeepSpeed-MII | Adding/editing source codes | pickle (unsafe), safetensors | decoder-only | - | ✘ | Python |
| llama.cpp | Adding/editing source codes | gguf | decoder-only | 2b, 3b, 4b, 5b, 6b, 8b | ✘ | C/C++ |
| llama2.c | Adding/editing source codes | llama2.c | decoder-only | - | ✘ | C |
| LMDeploy | Adding/editing source codes | pickle (unsafe), TurboMind | decoder-only | 4b, 8b | ✘ | C++, Python |
| Inferflow | Editing configuration files | pickle (safe), safetensors, gguf, llama2.c | decoder-only, encoder-decoder, encoder-only | 2b, 3b, 3.5b, 4b, 5b, 6b, 8b | ✔ | C++ |
Comparison between Inferflow and other inference engines